Getting started with Inseq
Note
An extended and interactive version of this tutorial is available in the Inseq repository
Inseq (Sarti et al., 2023) is a Pytorch-based toolkit for conducting interpretability analyses of sequence generation models. At the moment, the library focuses on text-to-text generation models and allows users to quantify input importance at every generation step using various attribution methods. At the moment, the library supports the following set of models and techniques:
Models
All the models made available through the AutoModelForSeq2SeqLM interface of the 🤗 transformers library (among others, T5, Bart and all >1000 MarianNMT variants) can be used in combination with feature attribution methods.
All the models made available through the AutoModelForCausalLM interface of the 🤗 transformers library (among others, GPT-2, GPT-NeoX, Bloom and OPT/Galactica).
Interpretability Methods
At the moment, Inseq supports some gradient- and perturbation-based feature attribution methods sourced from the Captum library and attention weights extraction methods.
However, we aim to support more state-of-the-art attribution approaches in the near future (see these summary issues for an overview of the considered additions).
The list of all available methods can be obtained by using the list_feature_attribution_methods() method. Each method points to its original implementation, and is documented in its docstring.
Installing Inseq
The latest version of Inseq can be installed from PyPI using pip install inseq. For installing the dev version and contributing, please follow the instructions in the Inseq readme.
The AttributionModel class
The AttributionModel class is a torch.nn.Module that seamlessly wraps any sequence generation model in the Hugging Face library to enable its interpretability. More specifically, the class adds the following capabilities to the wrapped model:
A
load()method to load the weights of the wrapped model from a saved checkpoint, locally or remotely. This is called when using theload_model()function, which is the suggested way to load a model.An
attribute()method used to perform feature attribution using the loaded model.Multiple utility methods like
encode(),embed()andgenerate()that are also used internally by theattributemethod.
AttributionModel children classes belong to two categories: architectural classes like EncoderDecoderAttributionModel defines methods that are specific to a certain model architecture, while framework classes like HuggingfaceModel specify methods that are specific to a certain modeling framework (e.g. encoding with a tokenizer in 🤗 transformers). The final class that will be instantiated by the user is a combination of the two, e.g. HuggingfaceEncoderDecoderModel for a sequence-to-sequence model from the 🤗 transformers library.
When a model is loaded with load_model(), a FeatureAttribution can be attached to it to specify which feature attribution technique should be used on it. Different families of attribution methods such as GradientAttributionRegistry are made available, each containing multiple methods (e.g. both IntegratedGradientsAttribution and DeepLiftAttribution are gradient-based methods).
The following image provides a visual overview of the hierarchy of AttributionModel and FeatureAttribution subclasses:
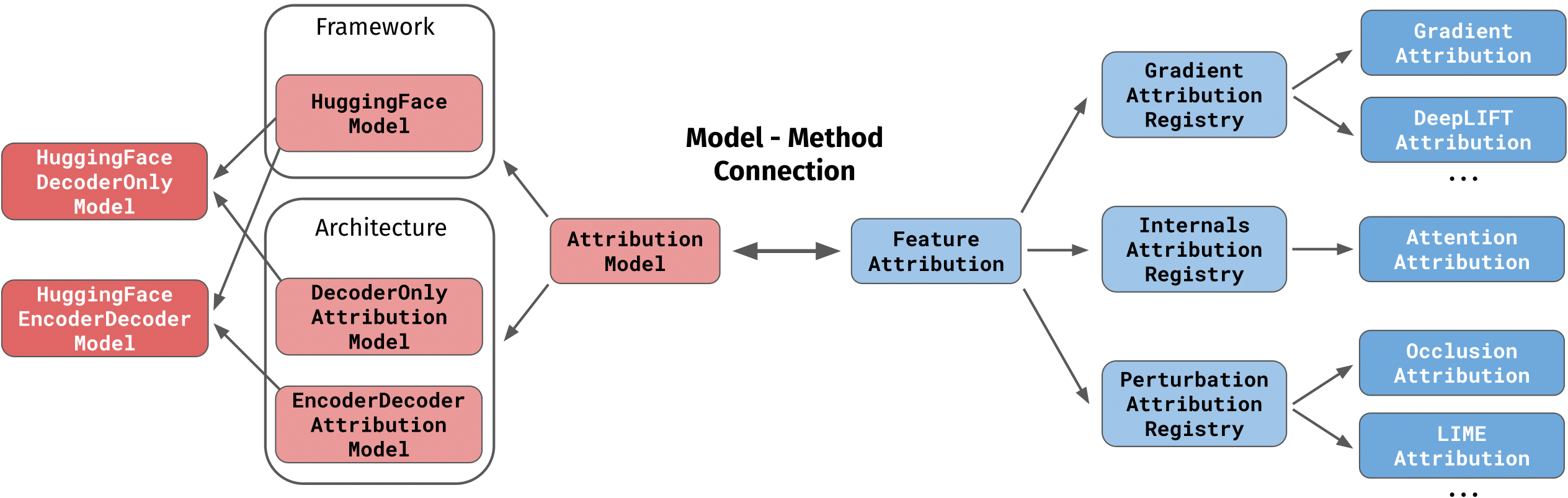
The attribute method
The attribute() method provides a easy to use and flexible interface to perform feature attribution using a sequence generation model and an attribution method. In its most simple form, a model and method are loaded together by passing their identifier to the load_model() method. Then, the selected model is used to generate one or more output sequences with customizable generation parameters. Finally, the generated sequences are attributed using the specified feature attribution method.
import inseq
# Load the model Helsinki-NLP/opus-mt-en-fr (6-layer encoder-decoder transformer) from the
# Huggingface Hub and hook it with the Saliency feature attribution method
model = inseq.load_model("Helsinki-NLP/opus-mt-en-fr", "saliency")
# Generate the translation for input_texts and attribute inputs at every steps of the generation
out = model.attribute(input_texts="Hello world, here's the Inseq library!")
# Visualize the attributions and step scores
out.show()
The attribute() method supports a wide range of possible customizations. Among others:
Specifying one string in
generated_textsfor every sentence ininput_textsallows attributing custom generation outputs. Useful to answer the question “How would the following output be justified in light of the inputs by the model?”. Using generate_from_target_prefix=True allows to use the specifiedgenerated_textsas prefixes and continue generation from there.attr_pos_startandattr_pos_endcan be used to attribute the generated spans between the selected indices, speeding up attribution when only a position of interest is present in the generated text.output_step_attributionswill fill thestep_attributionsproperty in the output object with a list of step attributions (i.e. per-generation step scores for all attributed examples). These are normally produced by the attribution process but then discarded after converting them in sequence attributions (i.e. per-example scores for all generation steps).attribute_targetis specific to encoder-decoder models, can be used to specify that target-side prefix should also be attributed besides the original source-to-target attribution. If specified, it populates thetarget_attributionfield in the output, which would otherwise be left empty. In the decoder-only case, the parameter is not used since only the prefix is attributed by default, and there is no source sequence.step_scoresallows for computing custom scores at every generation step, with some such as tokenprobabilityand output distributionentropybeing defined by default in Inseq.attributed_fnallows defining a custom output function for the model, enabling advanced use cases such as contrastive explanations.
The FeatureAttributionOutput class
In the code above, the out object is a FeatureAttributionOutput instance, containing a list of sequence_attributions and additional useful ìnfo regarding the attribution that was performed. In this example sequence_attributions has length 1 since a single sequence was attributed. Printing the output of the above result:
FeatureAttributionOutput({
sequence_attributions: list with 1 elements of type GranularFeatureAttributionSequenceOutput: [
GranularFeatureAttributionSequenceOutput({
source: list with 13 elements of type TokenWithId:[
'▁Hello', '▁world', ',', '▁here', '\'', 's', '▁the', '▁In', 'se', 'q', '▁library', '!', '</s>'
],
target: list with 12 elements of type TokenWithId:[
'▁Bonjour', '▁le', '▁monde', ',', '▁voici', '▁la', '▁bibliothèque', '▁Ins', 'e', 'q', '!', '</s>'
],
source_attributions: torch.float32 tensor of shape [13, 12, 512] on cpu,
target_attributions: None,
step_scores: {},
sequence_scores: None,
attr_pos_start: 0,
attr_pos_end: 12,
})
],
step_attributions: None,
info: {
...
}
})
The object FeatureAttributionOutput contains the following fields:
sequence_attributions: a list containingFeatureAttributionSequenceOutputper attributed sequence (in this case just one). These object contain the main information derived from the attribution process, includingsource_attributionsandtarget_attributions, the tokenizedsourceandtargetsequences and allstep_scoresthat were computed for the generation.step_attributionsare usually empty, but can be filled withFeatureAttributionStepOutput(per-step attributions across all examples instead of per-example attributions across all-steps, like sequence_attributions) by passing the parameteroutput_step_attributions=Truetoattribute.infois a dictionary containing a lot of information about the overall process, including attributed model and attribution methods, execution time and all parameters that were used for generation and attribution.
The tensor in the source_attribution field contains one attribution score per model’s hidden size (512 here) for every source token (13 in this example, shown in source) at every step of generation (12, shown in target). The GranularFeatureAttributionSequenceOutput is a special class derived by the regular FeatureAttributionSequenceOutput to automatically handle aggregation (see next section).
Both the FeatureAttributionSequenceOutput class and the visualization can be easily serialized as follows, to be reloaded later on for analysis:
out.save("marian_attribution.json")
# Reload the saved output
reloaded_out = inseq.FeatureAttributionOutput.load("marian_en_it_attribution.json")
html = reloaded_out.show(display=False, return_html=True)
with open("marian_attribution.html", "w") as f:
f.write(html)
Post-processing Attributions with Aggregators
You might have noticed that the shape of the source_attributions tensor in out has shape equal to [13, 12, 512] (source length x target length x hidden size) because we are using a gradient-based attribution method returning one importance score per hidden dimension, but when calling out.show() the visualized output is a matrix of shape [13, 12].
This is because every attribution method is automatically assigned an appropriate default Aggregator, which is called implicitly on show() to ensure that attributions can be visualized out-of-the-box. In this case the default aggregation involves taking the L2 norm of the hidden size (i.e. the magnitude of the importance score vector, strictly positive) and then normalize scores to ensure that all importance scores for every generated token (columns) across source_attributions and target_attributions sum to one. The normalization step is included since it allows us to express the relative importance of input features when generating the target token at every step.
We can see now another example using the attention attribution method, returning simply attention weights for the model (note that we do not need to reload the model, but it is sufficient to pass a new method identifier to model.attribute):
out = model.attribute(
input_texts="Hello everyone, hope you're enjoying the tutorial!",
attribute_target=True,
method="attention"
)
# out[0] is a shortcut for out.sequence_attributions[0]
out[0].source_attributions.shape
# >>> torch.Size([12, 16, 6, 8])
The attribution matrix produced by attention has dimensions (source length x sequence length x # layers x # attention heads), so out[0].source_attributions[:, 2, 3, 4] are attention weights associated to source tokens by the 4th attention head of the 3rd layer, produced when generating the 2nd target token. We can see the aggregation strategy employed by default as follows:
out[0]._aggregator
# >>> ["mean", "mean"]
out.show() # Shows a 2D matrix post mean-head and mean-layer aggregation.
This means that the mean of weights across all heads and layers is computed before showing the attributions. Let’s now try to customize the aggregation strategy to return a more specific view of the outputs using out.aggregate
Note
The list of Aggregator classes is available using list_aggregators(). The mean is an aggregation function (the list of aggregation functions is available using list_aggregation_functions()) which can be associated to an aggregator, but if not specified is used to aggregate the list dimension of the attribution by default (aggregator scores)
print("Aggregators:", inseq.list_aggregators())
print("Aggregation functions:", inseq.list_aggregation_functions())
# >>> Aggregators: ['spans', 'pair', 'subwords', 'scores']
# >>> Aggregation functions: ['vnorm', 'absmax', 'prod', 'sum', 'max', 'min', 'mean']
Understanding Inseq utilities with explain
Like Hugging Face, Inseq uses strings to identify many of its components (attribution methods, aggregators, aggregation functions, …).
Besides the list_XXX functions mentioned above that can be used to show available string identifiers, Inseq also provides an explain() utility to visualize the docstring of the class associated to the string identifier:
import inseq
inseq.explain("integrated_gradients")
# >>> Integrated Gradients attribution method.
# >>> Reference implementation:
# >>> `https://captum.ai/api/integrated_gradients.html <https://captum.ai/api/integrated_gradients.html>`__.
Custom Attribution Targets and Contrastive Attribution
Several feature attribution methods commonly compute gradients of feature vectors with respect to a prediction target (logits or probabilities), and use those as proxies of an explanation answering the question “How is this feature X influencing this model prediction P?”. However, in some cases we might want to compute attributions with respect to a different target to explain other properties of the prediction, e.g. the entropy (i.e. flatness/sharpness) of the probability distribution over the vocabulary.
A popular application of this idea involves using the difference in probability between an original and a contrastive option as a target for gradient-based attribution. This method, introduced by Yin and Neubig, (2022), is a principled way to obtain contrastive explanations answering the question “How is this feature X contributing to the prediction of A rather than B?”.
Inseq allows users to specify custom attribution targets using the attributed_fn parameter in attribute(). Attributed functions are simply step scores like probability values we extracted above (the probability is used as default attribution target). Custom scores can be registered using register_step_function() for more advanced use cases (an example is available in the documentation), but many including contrastive explanations (contrast_prob_diff) are already available out-of-the-box in the library, and can be listed with list_step_functions():
import inseq
attribution_model = inseq.load_model("Helsinki-NLP/opus-mt-en-it", "saliency")
# Perform the contrastive attribution:
# Regular (forced) target -> "Ho salutato il manager"
# Contrastive target -> "Ho salutato la manager"
out = attribution_model.attribute(
"I said hi to the manager",
"Ho salutato il manager",
attributed_fn="contrast_prob_diff",
# Special argument to specify the contrastive target, used by the contrast_prob_diff function
contrast_targets="Ho salutato la manager",
attribute_target=True,
# We also visualize the score used as target using the same function as step score
step_scores=["contrast_prob_diff"]
)
out.show()
This new example paints an even clearer picture in which the model is clearly biased in producing masculine when presented with gender-stereotypical professions.
Warning
Since contrast_prob_diff considers the difference in probabilities between 2 options (i.e. token A rather than token B), not all comparisons are meaningful. For example, helpless could be tokenized as _hel and pless, while helpful as _hel, pf and ul. Using contrastive attribution in this scenarios is not impossible, but remains an open research question. See the official tutorial for more details.
Conclusion and Let’s Build Together!
The Inseq library is relatively new and born out of a concerted effort of several PhD student and interpretability researchers. Our goal is to build a toolbox that is robust, flexible and easy to use to improve the reproducibility of research in interpretability for NLP. If you want to use Inseq in your research, or even better contribute to its developments, please reach out! We would be more than happy to help you out and discuss your ideas.